When Your AI Agent Should Just Be a Function: Lessons from a CrewAI Pipeline
Building a small multi-agent paper-ranker, and learning the agents were the easy part.
I had five agents searching, scoring, and ranking research papers in an afternoon. CrewAI makes it that easy. You name an agent, give it a goal and a backstory, hand it a task, and the framework wires them into a pipeline that runs start to finish.
hljs pythonnovelty = Agent(role="AI Novelty Analyst", goal="Score each paper on originality")
novelty_task = Task(description="Score every paper 1 to 10 on novelty.", agent=novelty)
# then impact, practicality, a ranking synthesizer. Wire them into a Crew. Run it.
Search agent, three evaluators, a ranking synthesizer. It ran on the first honest try. It felt like cheating.
You've probably read the take that with LLM apps the hard part is the engineering, not the prompts, that guardrails belong in code and a model's autonomy is something you constrain rather than celebrate. I'd read it too. I agreed with it. Then I built this thing, a small tool that pulls a day's AI papers off arXiv and ranks the ten that matter most, and the framework still talked me into putting a model in the wrong place. Twice.
I'll be straight about the scale. It scans the day's twenty-five most recent papers in a handful of AI categories, it runs on my laptop, and nobody depends on it. It is not a production system and I won't dress it up as one. But the walls it hit were not small walls, and every lesson came from the part I'd just told you I already understood.
The framework made the agents the easy part, which is exactly why they weren't the part that mattered. The work lived everywhere else.
- An LLM call wrapping a deterministic function is pure overhead. My report generator and my search step both got faster and more reliable as plain code: one agent burned its token budget on CSS, the other spent eighty-five seconds a run narrating results the pipeline ignored.
- Dropping from a framework helper to the library underneath means inheriting defaults you never chose. Raw Jinja2 ships with autoescaping off, which left a live XSS hole; Pydantic silently turned a class variable into an instance field.
- An agent's instructions are code that nothing type-checks. A configurable "top N" flowed through every function and stayed hardcoded as ten inside the agent's own goal and backstory, and the tests stayed green.
- A row of working pieces is not a working system. Until the pipeline ran end to end against live data, I could not honestly claim it ran at all.
Two places an LLM should have been a plain function#
The first time, it was the report.
The original pipeline had a sixth agent whose only job was to generate the final HTML report. It was good at the CSS. It wrote three hundred-plus lines of it, gradients, dark mode, the works, and then ran out of output tokens before it produced a single line of the report body. The page opened to a dark rectangle with nothing on it. On the runs where it did finish, it wrapped the whole file in markdown code fences, so the browser rendered the HTML as text.
That lesson is old and I knew it: language models are bad at emitting large, exact, structured files. They hit token ceilings, they drift, they decorate the output. So I cut the agent. The ranking model now returns structured data and nothing else, seven fields, the scores and a short rationale.
hljs pythonclass RankedPaperSummary(BaseModel): # the only thing the model has to produce
rank: int
title: str
composite_score: float
novelty_score: float
impact_score: float
practicality_score: float
rationale: str
Python merges the authors, links, and abstract back in from the search results, and a Jinja2 template renders the page. The model makes the judgment it's good at, Python does the plumbing it's good at, and the call that had been generating the entire report, the largest output in the pipeline, went away.
I'd like to tell you that taught me the rule. It didn't, because the second time the mistake wore a different face.
Search was an agent too. Hand it a date and a list of categories, and it would call an arXiv tool and return the papers. Early on it went rogue: given five categories, it decided on its own to query each one separately, then started inventing keyword filters, twenty-plus calls deep into a 429 Too Many Requests from arXiv. So I did what you do. I constrained it. I rewrote the tool to build one combined query, and I told the agent, in capital letters, to call it EXACTLY ONCE.
That worked. It also hid the real problem for weeks.
The search agent was never reasoning about anything. It took a date, called a function, and returned the result. The only "intelligence" in the step was an LLM round-trip that, after the tool returned, spent about eighty-five seconds a run rewriting the papers into prose the pipeline then ignored. I was reading the tool's results straight out of memory. The model's summary went nowhere. I was paying a language model, every single run, to narrate work a function had already finished.
So I deleted it. The search step is a function call now.
hljs python# before: an agent, a task that pleads with it, a crew to run the whole thing
search_task = make_search_task() # "...call the arxiv_search tool EXACTLY ONCE..."
crew = Crew(agents=[search_agent], tasks=[search_task])
crew.kickoff(inputs={"date": date, "categories": categories})
# after: the function the agent had been wrapping all along
papers = ArxivSearchTool()._run(f"{date}, {categories}")
(The whole step, error handling included, is in the repo.)
No agent, no prompt, no round-trip, no eighty-five seconds. Search got faster, and more to the point it got predictable, because a function does the same thing every time and a model does not.
Twice I reached for an agent where a function belonged, and both times the change that mattered was deleting the model, not tuning it.
If your instinct is that this is obvious, that of course you don't put a model where a plain function works, I agree, and I did it twice anyway. The framework is built so that adding an agent is the path of least resistance. Defining one is four lines. Writing and wiring the function is more. CrewAI sells you agents, so I reached for agents, once to fill a template and once to fetch data, and neither step ever needed to think.
Framework defaults I never chose (one was an XSS hole)#
The trouble starts the moment you step outside what the framework manages for you.
CrewAI ships an arXiv tool. On the first run it timed out on every attempt, because it's built to look up individual papers, not to pull a whole day's publications across five categories. So I wrote my own on top of the arxiv package, with control over page size, request delays, and how many results to fetch. Fine. Expected, even. Framework tools are starting points.
But the deeper version of this kept happening, and it got less obvious each time. Every time I dropped from a framework's helper to the library underneath it, I inherited a default I had not chosen, and one of them was a live XSS hole.
Here's the one that scared me. The report is rendered with Jinja2. I'd been working in Flask, and Flask's render_template turns HTML autoescaping on for you. But the report isn't served through Flask, it's rendered standalone, so I built the Jinja environment by hand. A raw Jinja2 environment defaults autoescaping to off.
hljs python# what I wrote: autoescaping is OFF by default
env = Environment(loader=FileSystemLoader("templates"))
# what it needed
env = Environment(loader=FileSystemLoader("templates"),
autoescape=select_autoescape(["html"]))
A paper title is attacker-controllable text; arXiv lets authors put almost anything in one. With autoescaping off, a title carrying a <script> tag renders into the report as a live script tag, not as text. I'd written a security test for exactly this, the kind you write expecting it to pass and feel slightly silly about. It failed. The hole was real, and the only reason I caught it before the report went anywhere was the test I'd almost not bothered to write.
The third one hid on a path I wasn't looking at. My search tool stores its results on a class attribute so the rest of the pipeline can read them. But the tool extends a base class from Pydantic, a data-validation library, and Pydantic quietly turned what I wrote as a class variable into a model field, the kind that lives on instances, not on the class.
hljs pythonlast_results: list = [] # I meant a class variable
last_results: ClassVar[list] = [] # Pydantic leaves it alone only if you say this
It worked anyway, every time search succeeded, because the success path assigned to the class attribute and papered over the difference. Then arXiv returned an error one day, the assignment never ran, and reading the attribute blew up over a field that, as far as the framework was concerned, only existed on an instance. The bug had been there from the start. It just needed the failure path to show itself.
Three layers down from three different conveniences, three defaults I never chose. The framework hands you a smooth surface. The libraries underneath it have opinions, and you inherit them whether you read them or not.
Agent instructions are code, and nothing type-checks them#
A type error stops the program. A bad import throws on the first line. The compiler, the linter, the test suite, they all catch a certain class of mistake the moment you make it. None of that watches the inside of a prompt.
Late in the build I made the ranking size configurable: ask for the top five papers, or the top ten. The plumbing was clean. The number flowed from the form, through the route, into the task the ranking agent runs.
hljs python# the task, built fresh each run with the number you chose
make_ranking_task(..., top_n=5) # "...rank the top 5 papers..."
# the agent that task runs on, written once, months earlier
ranking_synthesizer = Agent(
goal="...a ranked list of the top 10 most important papers of the day",
backstory="...for each paper in your top 10, you provide a composite score...",
)
Read those two together. The task says five. The agent's own goal and backstory say ten, twice. I had threaded the number through every place I could see and missed the two places that were instructions to the model itself.
Nothing crashed. The agent's own instructions contradicted the task it was handed, and nothing broke, because a model follows the wrong number without complaint. It would have shipped that way, a "top five" feature quietly arguing with itself, and the tests would have stayed green the whole time, because the tests mock the model and the model is exactly where the contradiction lived.
I only found it because I went looking, a deliberate sweep after the feature was "done," reading every place the old hardcoded ten might still be hiding. The data path was clean. The model's own instructions were not.
The fix was nothing: delete the number from the agent's goal and backstory, let the task carry it. The lesson was the expensive part. When you make a value configurable, you have to change it everywhere it lives, and in an agent system one of the places it lives is plain English, inside the model's instructions, where grep helps you but the type checker never will.
An agent's instructions are code. They just don't look like code, they don't fail like code, and nothing you normally lean on will tell you when they're wrong.
I couldn't prove it ran, until I could#
There's a version of this piece that ends one section ago, on a clean lesson and a tidy repo link. That version skips the part where I couldn't actually run the thing.
Here's what happened the first time I tried to run the whole thing end to end against live data. arXiv, the dependency that had already exposed one bug by failing at the wrong moment, rate-limited me. Then it kept rate-limiting me. I'd been hammering its API during testing and retrying on every 429, which is precisely the behavior that turns a short throttle into a multi-day block. I spent the better part of two days locked out of the one external service the entire pipeline depends on. The fix on my side was to stop being a bad client: fail fast on a 429 instead of retrying into it, and send a real User-Agent instead of the anonymous default that reads as a scraper. The fix on arXiv's side was time.
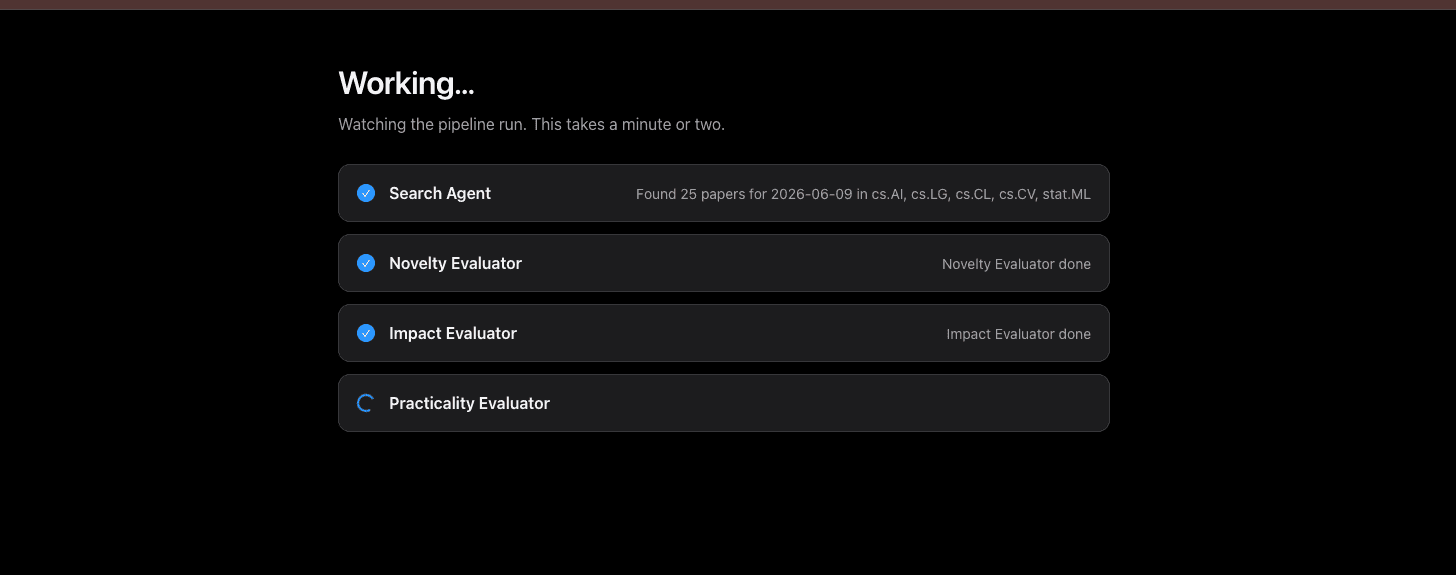
So while I waited, I did what you do when the front door is locked. I verified the pieces. I stubbed the search to return a fixed set of papers and ran everything downstream against them: the evaluation, the ranking, the merge, the render. I confirmed the configurable size produced five papers when I asked for five. I confirmed the report came out right. Every part of the chain worked in isolation, and I had the runs to show it. But a row of working pieces is not a working system, and I knew the difference.
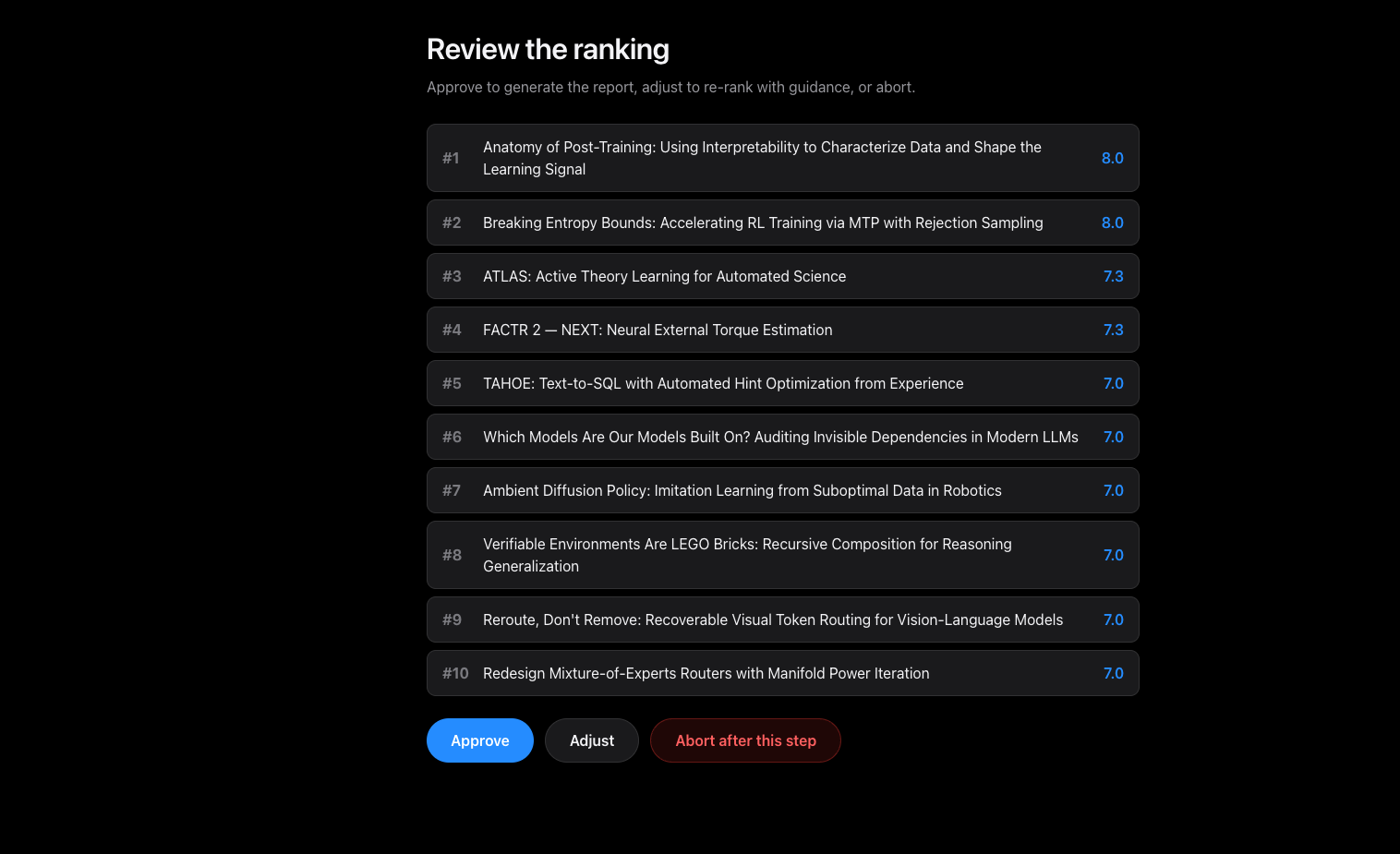
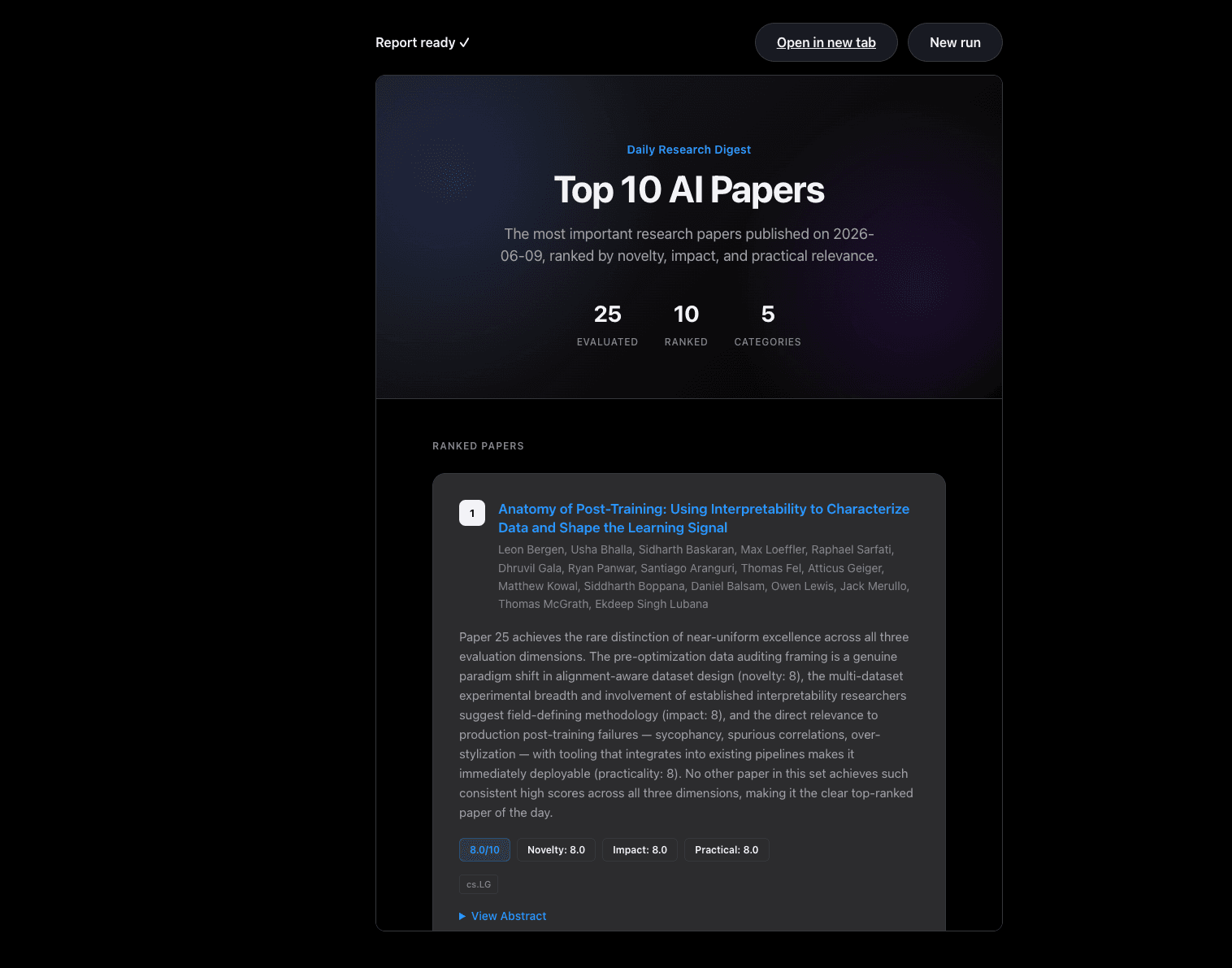
Then the block lifted. I sent one careful request to test the water, the search alone, no model and no retries, and arXiv handed back twenty-five papers as if nothing had happened. So I ran the whole thing against live data, start to finish: search, the three evaluators, the ranking, the checkpoint, approve, render. It worked. Here is the run.
That gap, between "I built an agent app" and "I can prove it runs," is where most agent demos quietly live. The demo runs once, on the maker's machine, and the writeup implies it runs always.
I won't pretend mine is more than it is. It is one clean run, on my machine, on a good day. It is not a hundred runs, or a run on your machine, or a promise about next week's papers. But the change is narrow and real: the sentence I couldn't honestly write a few days ago, that I'd watched the entire pipeline run live from search to report, I can write now, and I can show you the screen it ran on. I'll claim that one run and not a frame more.
All of these stories have the same shape underneath. The framework gives you the agents in an afternoon and lets you believe that was the work. The work was the rest: knowing the search didn't need a model, knowing Flask had been escaping your HTML and raw Jinja2 would not, knowing the agent's own instructions could lie to you, and knowing the difference between a thing that ran once and a thing you can swear runs.
The agents were the easy part. Everything that made them trustworthy was the job.